Practical AI for Product People

Everyone’s talking about AI these days—but sometimes it feels like we’re talking around it rather than about it. And there’s little discussion of how we build AI into our products. How can AI enhance your app experience? What new capabilities can you deliver? What existing functionality can you provider better, faster, cheaper? And what can’t you do?
As Product and UX folks, we look at customer needs and deploy a toolbox to meet them. AI expands that toolbox with interesting and sometimes-unexpected new tools; this article is an introduction to them. After reading it you’ll be better-equipped to say, “We can solve that user problem with a RAG system,” and just as importantly, “Sure, we can solve that but we don’t need AI.”
Background
Large Language Models (LLMs)
When we say “AI”, we’re usually referring to the generation of AI that began with ChatGPT in 2022. ChatGPT is a product built around platforms called “Generative Pre-trained Transformers” (GPT), which are large language models (LLMs). All the other AI platforms — Anthropic’s Claude, Google’s Gemini, Perplexity, DeepSeek, Llama — those are LLMs too.
So, what’s an LLM? It’s a word-prediction machine. After comprehensive training on an enormous amount of source material, it takes a prompt (“What’s a good name for a wombat who drives around in a tiny van solving mysteries?”) and predicts the most probable next word. And the word after that, and the one after that, and so on — ending up with, “A fun name for a wombat detective could be ‘Waldo Wheels.’” (According to GPT-4o).

LLMs don’t have concepts the way humans do. GPT-4o doesn’t know what a wombat is; it just predicts words. If I ask it, “What’s 1+1?” it will almost certainly give me 2, but it’s not adding two numbers; it’s effectively answering the question, “What do most people say?”
LLMs also lack memory — they’re one-shot. If you want an LLM to remember its previous response, you have to include that in your prompt.
It’s like having an infinite number of forgetful interns. (Props to Benedict Evans for the analogy.) They’re resourceful and tireless, but their skills are limited and they forget everything they do once they’ve done it:
- When you reply to ChatGPT with a follow-up, you’re not messaging the same intern as before. You’re messaging a new intern saying, “Hey, I had this exchange with one of your colleagues; can you read it and then respond?”
- You’ve probably heard about hallucinations; they’re great predictions that just happen to be fictional. The intern doesn’t know that: she found a pattern and extrapolated an answer; whether that answer is real or true isn’t really something she knows how to evaluate.
LLMs are amazing; they’re the biggest innovation in tech since the smartphone. (Some would say bigger.) They can do things easily that were expensive, difficult, or flat-out impossible before. Used correctly, they can unlock new and radically-improved capabilities in your product experience.
They’re also overhyped, misunderstood, dumb, and infuriating. Of course, so are computers in general. (And, for that matter, people.) And they’re impressively smart and dumb in new and different ways. GPT-4o gave me a great philosophical answer to, “When does 1 + 1 = 3?” But if I just want to crunch some numbers, I’m better off with Excel.
Beyond Chatbots
In “Chatbots: What Happened?”, my retrospective on the 2016–2017 chatbot craze, I wrote:
“[With chatbots], developers ended up trading one type of complexity for another; and users suddenly found themselves typing out instructions long-hand instead of tapping and swiping…but every digital interaction is a dialogue — whether it’s a simple text chat, an exchange of video and voice clips, a series of button presses, or manipulation of a chart. We can build it to be more or less explicitly conversational, but it doesn’t suddenly become unconversational when we introduce GUI.”
With ChatGPT as the gold standard for AI and everyone rushing to integrate LLMs into their products, that still rings true. If you’re tasked with realizing an executive-mandated “AI strategy,” a chatbot is the easy answer…but maybe not the best one vs. something GUI-based.
(By GUI I mean “graphical user interface”, the traditional paradigm for interacting with software first popularized by Apple with the Mac and carried over to smartphones — windows and buttons and drag-and-drop and stuff.)
Let’s look at an example with OpenAI’s 4o. I asked it for a photo of a cat hanging out with a beer in a cafe at twilight:

First, let’s pause and recognize how incredible that is.
Now, suppose I want to make a change. The poster top left feels a bit creepy to me, so let’s ask the LLM to replace it:

OK…sort of. It did replace the poster. It also changed all the other posters. And in fact everything in the image is just a little bit different. Maybe that’s fine, but it’s not what I asked for. And if I follow up with, “Keep everything else the same — just replace the one poster,” it removes all the other posters.
OpenAI just released 4o, and I had to rewrite this example because 4o is so much more accurate than its predecessor DALL-E. But the problem here goes beyond accuracy. It’s just awkward to specify these sorts of changes in a chat, e.g., “the upper poster in the second column of posters from the left over the cat’s head.” Simply put, I want to point at stuff.
And that’s doable. If I open Photoshop, select the poster, and prompt its Generative Fill feature, I get the exact change I wanted:
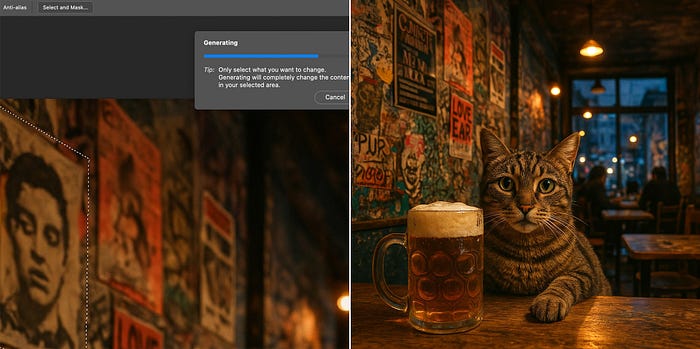
It’s a precise, one-step process because in Photoshop, I can select stuff — I’m using one of the core advantages of a GUI, direct manipulation, in concert with AI.
The 2016 hype cycle was specifically about chatbots. But today it’s about AI, with chatbots as the first generation of product experience. They’re a natural first step given how LLMs work, and there are plenty of chat-oriented use cases suited to this first generation of “AI-native” products. But I’m most excited about what comes after — what we can accomplish as we embed these tools in other types of system and get creative with them.
Introducing the AI Toolbox
The biggest surprise, when I really started digging into AI last year, was how easy it is.
It hasn’t always been. I co-founded an AI startup in 2012. I PM’d a machine-learning project at Google in 2014. These weren’t engineering roles, but even so I wanted a conceptual understanding of the tech. I watched Stanford machine-learning courses and internal Google training videos and tried to remember my college linear algebra…and sorta kinda half understood. Enough to do my job, yes, and also enough to know I wasn’t anywhere close to being a machine-learning engineer.
All that complexity is still there, of course: today’s AI builds on the work of that era. But OpenAI, Google, Anthropic, and friends have packaged it up so you don’t need to think about those innards.
Another surprise: there’s just a handful of key techniques — tools in your toolbox. The main ones: LLM prompting, image-generation, structured output, embeddings, and RAG.
You’ll apply these tools alongside non-AI techniques by building pipelines: chaining tools together to address your use cases with the right combination of control and flexibility. There are platforms like LangChain and Haystack designed to manage these pipelines, but you don’t necessarily need them; after all, software development is all about doing one thing after another.
This toolkit has an unfamiliar profile when it comes to performance. Even a simple LLM prompt can take a second or two; image-generation can take much, much longer. And that’s before you build multi-step pipelines. ChatGPT works well as a product, in part, because the chat paradigm expects “human latency.” The typing indicator, the answer coming in word by word, all make LLM slowness feel reasonable because we’re used to it from our human correspondents. If ChatGPT were a traditional website it would feel slow.
All of which is to say: you’ll spend more time addressing AI’s limitations than you will unlocking its benefits.
Owl Patch: AI Learning in Action
Throughout this article I’ll be referencing Owl Patch, a simple language-learning app I built. It’s a guessing game wherein you create vocabulary lists, then practice them by speaking hints to it; the app guesses which word you’re thinking of based on your hints. It’s simple and rough, but it works and made a great testbed for AI techniques.
Is Owl Patch my next Big Thing? Of course I’d love to discover it has that potential — I certainly find it useful in learning German — but I created it as a way to learn this stuff hands-on.
OK! Let’s look at what’s in the toolbox.
LLM-Prompting
If you’ve used ChatGPT this will feel familiar: put text in, get text out.
ChatGPT isn’t an LLM: it’s a product wrapped around one. It’s tailored to its use case and, as such, may give you better answers — but because there are product assumptions baked in, it’s also less flexible than hitting a model directly. For the raw experience, OpenAI has a Playground; Google has one, too.
There’s a handful of major providers, each with a handful of models. (Model is just another way of saying LLM — that’s what the M stands for.) Which is the best? There’s no single answer. Some are better for some things, some for others…you may find comparisons out there on the web, and you may also need to experiment.
And speaking of experimentation: if you’re a PM or designer but don’t code, you have a new opportunity to roll up your sleeves alongside your engineers. Sign into the playgrounds and do some prompt-engineering yourself.
LLMs are powerful but again, prone to hallucinations. (Newer models are dramatically better but far from hallucination-free.) For example: Owl Patch is designed to correct a user’s grammar on the fly. Often that works well; sometimes, it fails and produces something like, “You said, ‘This animal lives in Madagascar.’ That’s not quite right. Instead try, ‘This animal lives in Madagascar.’”

Prompt engineering is an art, not a science. Unlike a traditional API, the things you need to say aren’t designed. They’re emergent properties of the LLM. Even those who make the LLMs don’t know all the secrets — though it’s certainly worth reading guides like this one from OpenAI and this from Google. It reminds me a bit of SEO, actually: there’s a lot of advice out there; some of it might be good; some of it is superstition.
Lastly, pure LLM-prompting is of limited use in a pipeline because the output is unstructured. Unless you’re displaying a blob of text directly to the user, that blob is almost certainly not what your codebase needs. More on that in a moment.
Examples: LLM-Prompting
So of course there are chatbots: ChatGPT, Gemini, and Claude are fantastic. But beyond that:
- Summarization: take a document or set of documents and produce a short summary. (Here’s GPT-4o’s summary of this article.) This feels promising for a communication tool (and is already in the Gmail app) or a newsreader.
- Cross-Document Summarization: build a summary from multiple documents, maybe even across apps: imagine a “daily briefing” summarizing all your emails and Slack messages.
- Writing helpers. LLM-assisted writing is already ubiquitous: smart autocomplete is everywhere, products like DeepL and Grammarly can up-level your writing or alter its tone, and there’s even Gamma to create entire slide decks. I see an opportunity to get more specific and proactive: warn me when I forgot an attachment, prevent me sending overly-angry or no-longer-relevant messages, and so on.
- Naming things. Do you come up with excellent names for all your WhatsApp groups? I don’t. But I wish I did. An LLM could help. I plan to use LLM-prompting to auto-name word-lists in Owl Patch.
- Prototyping. A simple LLM prompt can provide an initial approximation of a more complex pipeline in a fraction of the time. For example: Owl Patch’s core interaction uses a single OpenAI service. It’s not perfect, but it will take time and multiple APIs to improve it — and in the meantime what’s there is already better than a proof of concept.
Image Generation
For me, image-generation LLMs like Google’s Imagen or OpenAI’s 4o offer a visceral way to appreciate both the wonder and the limitations of AI.
It’s useful to think of these as co-creation: you’re going to get something interesting, but not exactly what you had in mind initially. That’s true with text-based LLMs too, but somehow it feels more significant with images.
Prompt engineering is tricky here. For instance: with Owl Patch I want simple, recognizable images of the words and phrases users submit. DALL-E kept putting boxes around things. And sometimes boxes around the boxes. Telling it not to add boxes resulted in more boxes. And despite specific stylistic instructions, the images were all over the place — chaotic when displaying them in a grid.
So I turned to Google’s Imagen. It’s twice as fast, doesn’t put boxes around things, and its output provides a very consistent style.
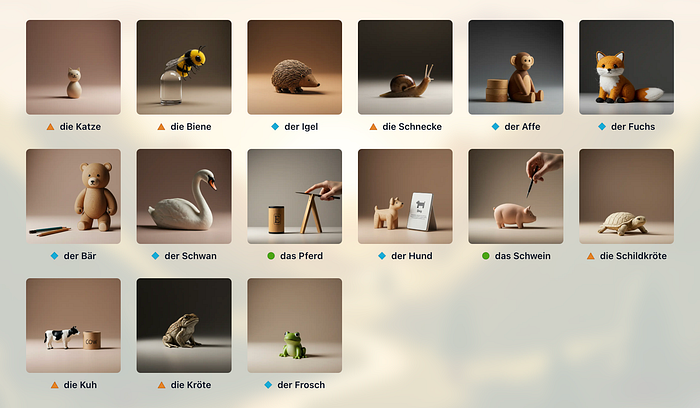
Does that mean Imagen is better? No. For a one-off image I often got better results from DALL-E. And Imagen failed to understand German at all: I had to build a simple pipeline, first prompting an LLM to translate and then passing it to Imagen.
LLMs can generate video, too. It’s powerful but I anticipate less need of it in most products — and while platforms like Sora are impressive, they still feel a little proof-of-concept to me.
Examples: Image Generation
- As with names, I suspect most people don’t create avatars for their WhatsApp groups, icons for folders in their Notes apps, and so on. For years, the note-taking app Bear has automatically selected icons for commonly-used tags like “Work” or “Journal.” It’s delightful, and a great reminder that you don’t need AI to feel smart — but AI opens up more possibilities.
- Ever send a GIF or meme, but wish it could be more personalized? Apple does this with its Memoji but maybe a cartoon version of yourself isn’t your style. Now your messaging app or plugin can do it, too.
- Auto-illustration: select some text in a doc you’re writing, then generate an image to go with it given not only the immediate selection but the context of the entire doc, and even of other things you’ve written.
Structured Output & Tool Use
LLM-prompting often works poorly inside a product: when you’re building a pipeline, or need to integrate LLM results into your UI or database, raw unstructured text is problematic. “The three largest cities in Germany are Berlin with 3.7 million people, Hamburg with 1.9 million, and Munich with 1.5 million,” is great if you’re just displaying it verbatim; but if you want to show a formatted list with icons or a graph, you need structure.
That’s where structured output comes in (as in OpenAI’s Structured Outputs). As part of your API request, you provide a structure (city name as a string, population as a number, and so on), and the platform will ensure that its response conforms to it.
“Function calling” or “tool use” takes this further with different formats for different situations. It provides not only a format for the response, but a structured way to branch your pipeline. You define a set of potential next actions (”tools” or “functions”) along with the different parameters those actions need; the LLM chooses one depending on the request, then hands you its choice and the correctly-formatted data to send along.
For instance, suppose I’m building a personal shopping assistant. If the user says, “Order more cat food,” I want to search past orders for cat food and offer to re-order whatever she got last time. If instead she says, “I need a new shirt,” I might respond with a clarifying question — which type of shirt does she want? — and a set of options. These are two branches in my pipeline, two tools — the search-my-order-history tool and the provide-clarification-via-choice tool — and I can ask the LLM to choose the most appropriate one.
In general, “tool use” doesn’t actually use the tools — it returns the name of the tool and the format you specified and then you hook it up. That’s probably a good thing from a safety and security standpoint. That said, the major platforms do have a few built-in tools you can use directly like OpenAI’s web search, file search, and computer use.
Agents
There’s a lot of hype around agents these days. The term is a little buzzy and ill-defined; at their core, agents are AI-based apps that do stuff. What stuff? That’s where the “tool” in “tool use” comes in.
Are agents the future? Or a bad idea riddled with potential errors and security holes? It all depends on the tools you choose and how you hook them up. I’d argue you want tools that are constrained (they can only do so much damage), confirmable, and ideally undoable.
So an agent that autonomously buys stuff on Amazon with your credit card? Probably a bad idea. A customer-service bot that can upgrade subscriptions, provide basic tech support, help with changes of address, and so on? This appears to be what Sierra is building and it makes sense to me: again, these actions are constrained (upgrading a subscription can only do so much damage), confirmable (you can provide GUI to ensure it’s what the user wants), and undoable (you can downgrade again).
Examples: Tool Use
Tool Use is liable to be the workhorse of any LLM pipeline so it’s tempting to say, “You can use it for everything!” But more specifically:
- Owl Patch uses structured output for newly-submitted words, prompting an LLM for the English translation and German grammatical gender and then passing those to other stages in its pipeline (storing in the database, generating an image).
- At Outgoing (the startup I work for) we’re building an app to recommend local activities (restaurants, live events, etc.) to users based on a freeform query like, “Find me a great ramen place for lunch tomorrow.” Function-calling helps us refine the query: our back end evaluates it, determines what additional information might be needed, and selects a tool to obtain it: a simple follow-up question, a list of predefined options, etc.
- A to-do app could use function-calling to enrich different tasks in different ways: “cancel Post subscription” might match the “web-based action” tool and return the relevant subscription-management URL; “get rid of Post subscription” might match the “notify about duplicate” function and include the ID of the other task.
- A spreadsheet could have a “smart toolbar” that provides 3 suggested actions based on a prompt combining the user’s last few actions. Simple structured output would provide a list of those; function-calling could provide the parameters to make them single-click.
Embeddings
Embeddings are a powerful, fast way to understand, compare, and cluster chunks of text based on their meanings.
Let’s say I have a “document” consisting of the sentence, “I’ve gone to the bank and withdrawn €20.” If I generate an embedding for it, I now have a vector.
What’s a vector? It’s a point in multidimensional space. Each dimension — X, Y, and Z in three dimensions — represents some aspect of the documents in the space. Maybe the X dimension represents something like “finance”, Y is “errands,” and Z is “tacos”. Our document gets high values for X and Y, and a low value for Z.
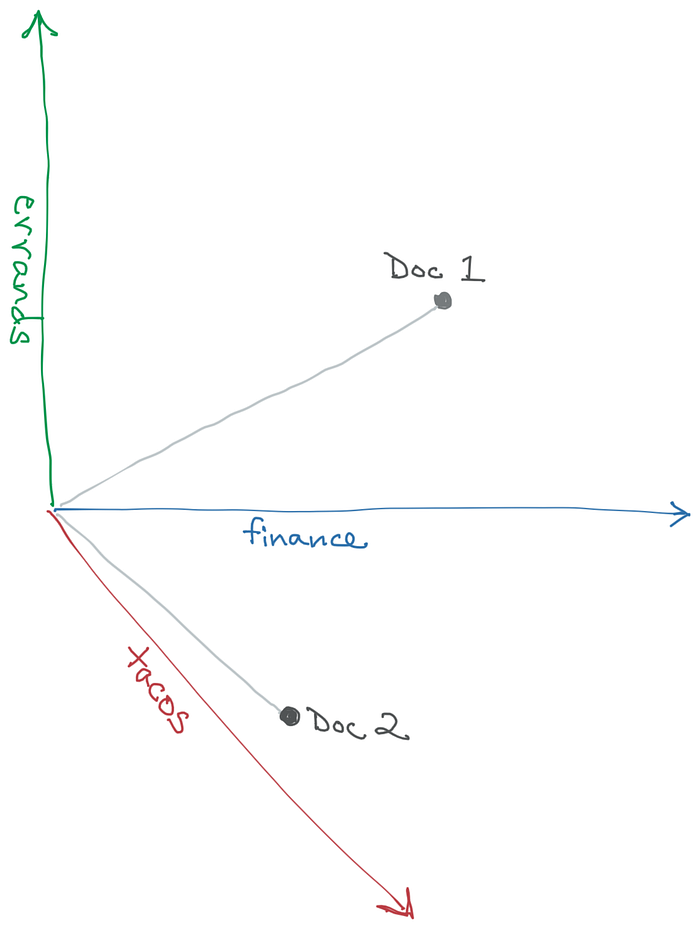
Let’s add a second document: “Dave is withdrawn these days, and spends all his time moping and eating tacos on the bank of the river.” Because today’s embeddings are powered by LLMs, they understand semantics rather just words. So even though both documents mention “bank” and “withdrawn,” that won’t give us false equivalency. Doc #2 gets low values for X and Y, and a high value for Z.
It’s easy to envision three dimensions, but of course there’s more to life than money and tacos. (Spicy chicken wings, for example.) OpenAI’s smallest embedding model has 1536 dimensions and Google’s has 768. I’m a visual thinker so all those dimensions make my brain hurt…but whether it’s 3 or 3000, the concept is the same.
Now that we have documents in our “embedding space,” it becomes easy to compare them — we just look at how close together or far apart they are. You can do this with a purpose-built “vector database” like Pinecone or Weaviate, but the database you already use in your product probably supports them, too (e.g., PostgreSQL or Firebase). Those similarity calculations are as simple as a database query — no further AI required.
So: embeddings are a way to figure out how similar chunks of text are in their meaning, using an LLM only once per chunk.
Embeddings: Examples
- Search a collection of documents. Ahead of time, generate embeddings for each document and store them in your database. When the user submits a search, generate an embedding for it — that is, treat it just like any other document. Query your database for whichever documents are “near” the search vector-wise. One of my first AI-learning projects did this for all my Notion notes and was able to answer questions like, “Who did I talk to last year about international moving companies?”
- Sort to-dos into categories. This was another early learning project — given a list of categories like Errands, Chores, Reading, and so on (with embeddings computed for each), categorize a new to-do (”Take out the trash”) based on whichever category is nearest.
- Or, how about implicit categories? Given this to-do, which others are similar enough that I should consider doing them together? Which might deserve to be combined into a project?
- Embeddings play a crucial role in Outgoing’s local-activity search: we store embeddings for every activity in our database, then use their similarity to the user’s query as a key component of our pipeline.
- For Owl Patch I’m planning a suggestion feature: I’ll generate embeddings for, say, the 5000 most common words. Then, when a user adds a word, Owl Patch can suggest words that might work well alongside it in the guessing game.
Retrieval-Augmented Generation (RAG)
RAG is itself a pipeline, but a common enough one to deserve a brief mention. It applies the general-purpose power of an LLM to a constrained set of documents: answers come purely from that collection rather than the entire store of knowledge on which the LLM was trained. (One side effect: fewer hallucinations.) It works like this:
- Start with an embedding-based document search as described above: choose documents in your vector database that are similar in meaning to the prompt.
- Prompt an LLM to summarize or compose and answer from only those documents — that is, pass the docs and search query as part of your prompt along with instructions like, “These documents are all relevant to this search query; please summarize them in a way that’s pertinent to the search.”
Sophisticated RAG systems will add more steps to enhance the result, but that’s the basic idea.
It’s not hard to build a simple RAG system, but in addition OpenAI offers a prepackaged one with its File Search tool.
Example Use Cases
Once you know what RAG is, you’ll realize how many AI startups look like RAG systems:
- Enterprise search: intelligently query your company’s Slack, Teams, Google Drive, project-management system, Notion, etc.
- Customer-support database (or chatbot): same idea.
- One I haven’t seen: a “related messages” feature in a communication app. Select an email or Slack message, see a summary of related messages with links to the threads.
AI vs. UX
With this toolbox, your products can do remarkable things — things that weren’t possible before, or would have required a team of PhDs.
But one thing hasn’t changed: great products center on smooth interaction between people and tech — and humans are the same as they’ve always been. Faced with cool new technology, it’s easy to lose sight of that truth. When we do, we deliver products that are very intelligently unintelligent. Here are two signs you might be on that path:
- You have an “AI team,” “AI initiatives,” or “AI strategy”. These aren’t always bad, but they’re often hallmarks of a mandate to build “AI Things” rather than great products that leverage AI. Your primary use case isn’t, “As a user…”, it’s “As a company, we need to put an AI thing in the product because AI.”
- Every screen now has a little sparkly-icon button that your user can invoke to “do AI stuff.” Same problem: a sparkly-icon button says, “Click here to do AI Things!” and that’s not what your users are here for.
And you don’t always need AI in order to be “smart”. Apple (which is behind on AI right now) built its brand on products that “just work” — that do the right thing, that ensure the functionality you need is at your fingertips. They’ve been credibly releasing things with “magic” in the name for years, no AI required.
So as always: start with the user or customer. Understand their needs. And then bring your expanded toolbox to bear on the problem. Invest in building fantastic products, and invest wisely.
Thanks to Shanan Delp, Carsten Spremberg, Balach Hussain, Cass Sapir, Roland Butler, and Berlin’s ProductLab community for their feedback on drafts of this article.
